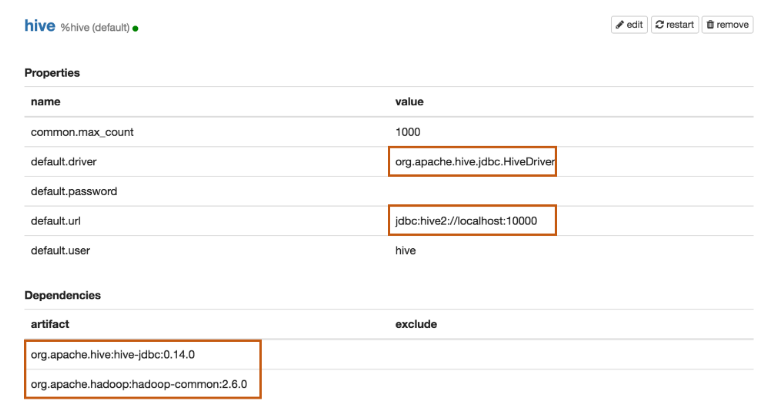
export SPARK_HOME=/usr/lib/spark
# 아래 설정은 해도 되고 안해도 된다.
# set hadoop conf dir
export HADOOP_CONF_DIR=/etc/hadoop/conf
# set options to pass spark-submit command
export SPARK_SUBMIT_OPTIONS="--packages com.databricks:spark-csv_2.10:1.2.0"
# extra classpath. e.g. set classpath for hive-site.xml
export ZEPPELIN_INTP_CLASSPATH_OVERRIDES=/etc/hive/conf
그리고 yarn 모드는 다음과 같이 있는데, 적절한 것으로 선택한다. 보통 yarn-client나 yarn-cluster를 사용한다.
local[*] in local mode
spark://master:7077 in standalone cluster
yarn-client in Yarn client mode
yarn-cluster in Yarn cluster mode
mesos://host:5050 in Mesos cluster
java 설정이나 pyspark python 버전등을 바꾸려면 다음 설정등을 넣어줄 수 있다.
여기까지가 기본설정이며, 보통의 경우 위 설정만 해주면 zeppelin을 잘 사용할 수 있다.
다음은 kerberos가 적용된 hadoop Secure Mode일 때 설정이다. 다음 설정을 추가해준다.
# 위에서는 안해도 됐지만, 이번엔 해야한다.
export HADOOP_CONF_DIR=/etc/hadoop/conf
export KRB5_CONFIG=[krb 설정 경로]
export LIBHDFS_OPTS="-Djava.security.krb5.conf=${KRB5_CONFIG} -Djavax.security.auth.useSubjectCredsOnly=false"
export HADOOP_OPTS="-Djava.security.krb5.conf=${KRB5_CONFIG} -Djavax.security.auth.useSubjectCredsOnly=false ${HADOOP_OPTS}"
export ZEPPELIN_INTP_JAVA_OPTS="-Djava.security.krb5.conf=${KRB5_CONFIG} -Djavax.security.auth.useSubjectCredsOnly=false"
export JAVA_INTP_OPTS="-Djava.security.krb5.conf=${KRB5_CONFIG} -Djavax.security.auth.useSubjectCredsOnly=false ${JAVA_INTP_OPTS}"
# 경우에 따라 spark-submit 시에 아래 설정이 필요할 수 있다.
export SPARK_SUBMIT_OPTIONS="--keytab [keytab경로] --principal [principal]"
위에 있는 -Djavax.security.auth.useSubjectCredsOnly=false 옵션이 없으면 아래와 같은 에러가 발생할 수 있다.(이것때문에 시간을 많이 버렸다 ㅠ)
ERROR [2019-12-20 17:41:57,275] ({pool-2-thread-2} TSaslTransport.java[open]:315) - SASL negotiation failure
javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211)
at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)
at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:271)
at org.apache.thrift.transport.TSaslClientTransport.open(TSaslClientTransport.java:37)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport$1.run(TUGIAssumingTransport.java:52)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport$1.run(TUGIAssumingTransport.java:49)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport.open(TUGIAssumingTransport.java:49)
at org.apache.hive.jdbc.HiveConnection.openTransport(HiveConnection.java:190)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:163)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:105)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:208)
at org.apache.commons.dbcp2.DriverManagerConnectionFactory.createConnection(DriverManagerConnectionFactory.java:79)
at org.apache.commons.dbcp2.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:205)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:861)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:435)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:363)
at org.apache.commons.dbcp2.PoolingDriver.connect(PoolingDriver.java:129)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:270)
at org.apache.zeppelin.jdbc.JDBCInterpreter.getConnectionFromPool(JDBCInterpreter.java:425)
at org.apache.zeppelin.jdbc.JDBCInterpreter.access$000(JDBCInterpreter.java:91)
at org.apache.zeppelin.jdbc.JDBCInterpreter$2.run(JDBCInterpreter.java:474)
at org.apache.zeppelin.jdbc.JDBCInterpreter$2.run(JDBCInterpreter.java:471)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.zeppelin.jdbc.JDBCInterpreter.getConnection(JDBCInterpreter.java:471)
at org.apache.zeppelin.jdbc.JDBCInterpreter.executeSql(JDBCInterpreter.java:692)
at org.apache.zeppelin.jdbc.JDBCInterpreter.interpret(JDBCInterpreter.java:820)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:103)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:632)
at org.apache.zeppelin.scheduler.Job.run(Job.java:188)
at org.apache.zeppelin.scheduler.ParallelScheduler$JobRunner.run(ParallelScheduler.java:162)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
at sun.security.jgss.krb5.Krb5InitCredential.getInstance(Krb5InitCredential.java:147)
at sun.security.jgss.krb5.Krb5MechFactory.getCredentialElement(Krb5MechFactory.java:122)
at sun.security.jgss.krb5.Krb5MechFactory.getMechanismContext(Krb5MechFactory.java:187)
at sun.security.jgss.GSSManagerImpl.getMechanismContext(GSSManagerImpl.java:224)
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:212)
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:179)
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:192)
... 43 more
INFO [2019-12-20 17:41:57,278] ({pool-2-thread-2} HiveConnection.java[openTransport]:194) - Could not open client transport with JDBC Uri: jdbc:hive2://[hive주소]/;principal=hive/[principal주소]
ERROR [2019-12-20 17:41:57,278] ({pool-2-thread-2} JDBCInterpreter.java[getConnection]:478) - Error in doAs
java.lang.reflect.UndeclaredThrowableException
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1643)
at org.apache.zeppelin.jdbc.JDBCInterpreter.getConnection(JDBCInterpreter.java:471)
at org.apache.zeppelin.jdbc.JDBCInterpreter.executeSql(JDBCInterpreter.java:692)
at org.apache.zeppelin.jdbc.JDBCInterpreter.interpret(JDBCInterpreter.java:820)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:103)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:632)
at org.apache.zeppelin.scheduler.Job.run(Job.java:188)
at org.apache.zeppelin.scheduler.ParallelScheduler$JobRunner.run(ParallelScheduler.java:162)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://[hive주소]/;principal=hive/[principal주소]: GSS initiate failed
at org.apache.hive.jdbc.HiveConnection.openTransport(HiveConnection.java:215)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:163)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:105)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:208)
at org.apache.commons.dbcp2.DriverManagerConnectionFactory.createConnection(DriverManagerConnectionFactory.java:79)
at org.apache.commons.dbcp2.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:205)
at org.apache.commons.pool2.impl.GenericObjectPool.create(GenericObjectPool.java:861)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:435)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:363)
at org.apache.commons.dbcp2.PoolingDriver.connect(PoolingDriver.java:129)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:270)
at org.apache.zeppelin.jdbc.JDBCInterpreter.getConnectionFromPool(JDBCInterpreter.java:425)
at org.apache.zeppelin.jdbc.JDBCInterpreter.access$000(JDBCInterpreter.java:91)
at org.apache.zeppelin.jdbc.JDBCInterpreter$2.run(JDBCInterpreter.java:474)
at org.apache.zeppelin.jdbc.JDBCInterpreter$2.run(JDBCInterpreter.java:471)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
... 14 more
Caused by: org.apache.thrift.transport.TTransportException: GSS initiate failed
at org.apache.thrift.transport.TSaslTransport.sendAndThrowMessage(TSaslTransport.java:232)
at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:316)
at org.apache.thrift.transport.TSaslClientTransport.open(TSaslClientTransport.java:37)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport$1.run(TUGIAssumingTransport.java:52)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport$1.run(TUGIAssumingTransport.java:49)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.hive.thrift.client.TUGIAssumingTransport.open(TUGIAssumingTransport.java:49)
at org.apache.hive.jdbc.HiveConnection.openTransport(HiveConnection.java:190)
... 33 more
INFO [2019-12-20 17:41:57,285] ({pool-2-thread-2} SchedulerFactory.java[jobFinished]:120) - Job 20191220-170645_132084413 finished by scheduler org.apache.zeppelin.jdbc.JDBCInterpreter1849124988
그리고, ${SPARK_HOME}/conf/spark-defaults.conf 에 kerberos 설정을 넣어준다.
spark.yarn.principal
spark.yarn.keytab
위 설정이 잘 적용되는지 확인해봐야 한다. 만약 안될 시에는 zeppelin interpreter 설정에 추가해준다.